介绍
Presto是由 Facebook 推出的一个基于Java开发的开源分布式SQL查询引擎,适用于交互式分析查询,数据量支持TB到PB字节。Presto本身并不存储数据,但是可以接入多种数据源,并且支持跨数据源的级联查询。
到目前为止 Presto 有两大分支: PrestoDB 和 Trino(原名PrestoSQL后来改为Trino)。两个发行版都满足基本功能,只是在技术细节有细微差别。如底层通信方式、对部分文件的读取速度。总的来说,各有优劣。
PrestoDB:根红苗正,有大厂支持;
Trino:PrestoDB 之父的原班人马支持,社区更活跃;
注:Presto 1不是通用的关系数据库。它不能替代 MySQL、PostgreSQL 或 Oracle 等数据库。设计Presto的目的并不是处理OLTP型事务。
1.基本概念
1.1 术语
1.2 特点
Presto引擎相较于其他引擎的特点正如⽂章标题描述的这样,多源就是它可以⽀持跨不同数据源的联邦查询,即席即实时计算,将要做的查询任务实时拉取到本地进⾏现场计算,然后返回计算结果。除此之外,对于引擎本身,它有⼏个值得关注的特点:
-
多租户:它⽀持并发执⾏数百个内存、I/O以及CPU密集型的负载查询,并⽀持集群规模扩展到上千个节点;
-
联邦查询:它可以由开发者利⽤开放接⼝⾃定义开发针对不同数据源的连接器(Connector),从⽽⽀持跨多种不同数据源的联邦数据查询;
-
内在特性:为了保证引擎的⾼效性,Presto还进⾏了一些优化,例如基于JVM运⾏,Code-Generation等。
1.3 应用场景
Presto 的应⽤场景⾮常⼴泛,接下来我们主要介绍⼏种使⽤⽐较⼴泛的场景进⾏介绍。
-
交互式分析:交互式查询是Presto主打的应⽤场景,Presto的即席计算特性和内部设计机制就是为了能够更好地⽀持⽤户进⾏交互式分析。可以类⽐⽤户基于Hive交互式查询HDFS中的数据,⽤户可以基于Presto查询各种不同的数据源的数据;
-
批量 ETL;
-
Facebook 的 A/B Test 基础架构也是基于Presto 构建的。
2.整体架构图
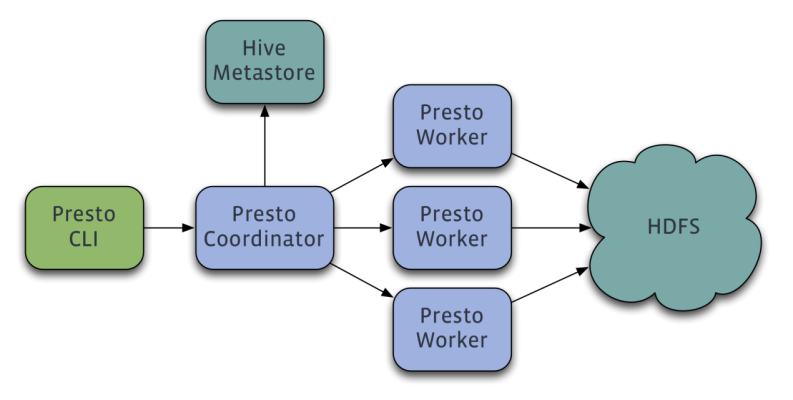
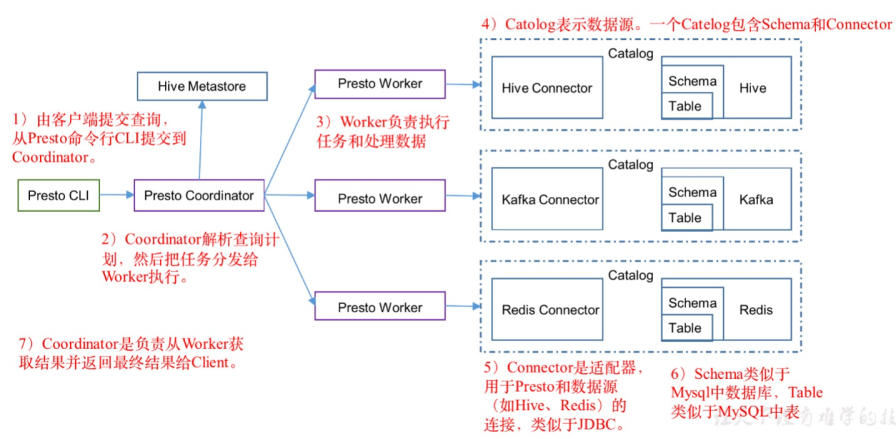
Presto查询引擎是一个Master-Slave的架构,由一个Coordinator节点,一个Discovery Server节点,多个Worker节点组成,Discovery Server通常内嵌于Coordinator节点中。Coordinator负责解析SQL语句,生成执行计划,分发执行任务给Worker节点执行。Worker节点负责实际执行查询任务。Worker节点启动后向Discovery Server服务注册,Coordinator从Discovery Server获得可以正常工作的Worker节点。如果配置了Hive Connector,需要配置一个Hive MetaStore服务为Presto提供Hive元信息,Worker节点与HDFS交互读取数据。
![adgagdfgdsgdsga.png]()
![YKYUKRKSDFGSDG.png]()
安装部署
jdk 版本
目前最新的presto版本是0.181,要求jdk不能低于1.8.0_92
步骤
1.在slave1节点上安装coordinator
tar -zxvf presto-server-0.181.tar.gz
cd presto-server-0.181
mkdir etc
cd etc
mkdir catalog
#这个是数据目录,存放日志以及一些配置文件
mkdir -p /home/qun/data/presto
1.1配置Node Properties
-
vi etc/node.properties
node.environment=production node.id=ffffffff-ffff-ffff-ffff-ffffffffffff node.data-dir=/home/qun/data/presto注意node.id在整个集群必须唯一,值可以随便填,没有固定格式
1.2配置JVM Config
-
vi etc/jvm.config
-server -Xmx16G -XX:+UseG1GC -XX:G1HeapRegionSize=32M -XX:+UseGCOverheadLimit -XX:+ExplicitGCInvokesConcurrent -XX:+HeapDumpOnOutOfMemoryError -XX:+ExitOnOutOfMemoryError1.3配置Config Properties
-
vi etc/config.properties
coordinator=true node-scheduler.include-coordinator=false http-server.http.port=8999 query.max-memory=2GB query.max-memory-per-node=1GB discovery-server.enabled=true discovery.uri=http://slave1:89991.4设置log
-
vi etc/log.properties
com.facebook.presto=INFO1.5添加mysql connector(可选,此处仅作为示例)
-
vi etc/catalog/mysql.properties
connector.name=mysql connection-url=jdbc:mysql://192.168.1.116:3306 connection-user=root connection-password=1234561.6添加hive connector(可选,此处仅作为示例)
-
vi etc/catalog/hive.properties
connector.name=hive-hadoop2 hive.metastore.uri=thrift://emr114.dtwave.com:9083 hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/etc/hdfs-site.xml2.在slave2节点上安装worker
将slave1上配置好的安装包复制到slave2节点上
scp -r presto-server-0.181 qun@slave2:~/2.1创建数据目录
mkdir -p /home/qun/data/presto2.2修改Config Properties
-
vi etc/config.properties
coordinator=false http-server.http.port=8999 query.max-memory=2GB query.max-memory-per-node=1GB discovery.uri=http://slave1:8999和coordinator不一样的是coordinator=false,代表这是一个worker节点
2.3配置Node Properties
-
vi etc/node.properties
node.environment=production node.id=ffffffff-ffff-ffff-ffff-fffffffffff1 node.data-dir=/home/qun/data/presto和coordinator不一样的是node.id=ffffffff-ffff-ffff-ffff-fffffffffff1,node.id必须集群唯一
2.4presto安装后,包结构如下
[qun@slave2 presto-server-0.181]$ tree -I *.jar
.
|-- bin
| |-- launcher
| |-- launcher.properties
| |-- launcher.py
| `-- procname
| `-- Linux-x86_64
| `-- libprocname.so
|-- etc
| |-- catalog
| | `-- mysql.properties
| |-- config.properties
| |-- jvm.config
| `-- node.properties
|-- lib
|-- NOTICE
|-- plugin
| |-- accumulo
| |-- atop
| |-- blackhole
| |-- cassandra
| |-- example-http
| |-- hive-hadoop2
| |-- jmx
| |-- kafka
| |-- localfile
| |-- memory
| |-- ml
| |-- mongodb
| |-- mysql
| |-- postgresql
| |-- presto-thrift
| |-- raptor
| |-- redis
| |-- resource-group-managers
| |-- sqlserver
| |-- teradata-functions
| `-- tpch
`-- README.txt
3.启动集群
在所有的节点上执行如下命令,一般情况下先启动coordinator,再启动worker
./bin/launcher start
./bin/launcher start
日志如下:
[qun@slave2 log]$ ll /home/qun/data/presto/var/log/
总用量 8388
-rw-rw-r-- 1 qun qun 8306295 7月 30 22:40 http-request.log
-rw-r--r--. 1 qun qun 1512 7月 29 21:24 launcher.log
-rw-rw-r-- 1 qun qun 26582 7月 30 17:37 server.log
安全认证
Presto集群开启Kerberos认证可只配置Presto Coordinator和Presto Cli之间进行认证,集群内部通讯可不进行认证。Presto Coordinator和Presto Cli之间的认证要求两者采用更为安全的HTTPS协议进行通讯。
若Presto对接的是Hive数据源,由于其需要访问Hive的元数据和HDFS上的数据文件,故也需要对Hive Connector进行Kerberos认证。
1.在coordinator节点上安装kerberos client
yum install krb5-libs.x86_64 krb5-workstation.x86_64 krb5
修改/etc/krb5.conf
[root@slave1 qun]# vi /etc/krb5.conf
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
[libdefaults]
default_realm = XIAOMI.PRESTO
dns_lookup_realm = false
dns_lookup_kdc = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
[realms]
XIAOMI.PRESTO = {
kdc = xiaobin
admin_server = xiaobin
}
[domain_realm]
.xiaomi.presto = XIAOMI.PRESTO
xiaomi.presto = XIAOMI.PRESTO
2.生成keytab,在slave1节点上执行如下命令,生成qun.keytab
kadmin -p admin/admin -q "addprinc -randkey qun@XIAOMI.PRESTO"
kadmin -p admin/admin -q "addprinc -randkey qun/slave1@XIAOMI.PRESTO"
kadmin -p admin/admin -q "ktadd -k /etc/qun.keytab qun@XIAOMI.PRESTO"
kadmin -p admin/admin -q "ktadd -k /etc/qun.keytab qun/slave1@XIAOMI.PRESTO"
3.生成keystore
需要注意的是alias需要和启动presto的用户名一样
[root@slave1 qun]# keytool -genkeypair -alias qun -keyalg RSA -keystore qunkeystore.jks
输入密钥库口令:
再次输入新口令:
您的名字与姓氏是什么?
[Unknown]: slave1
您的组织单位名称是什么?
[Unknown]:
您的组织名称是什么?
[Unknown]:
您所在的城市或区域名称是什么?
[Unknown]:
您所在的省/市/自治区名称是什么?
[Unknown]:
该单位的双字母国家/地区代码是什么?
[Unknown]:
CN=slave1, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown是否正确?
[否]: y
输入 <qun> 的密钥口令
(如果和密钥库口令相同, 按回车):
再次输入新口令:
4.配置jdk,Java Cryptography Extension Policy Files
wget http://download.oracle.com/otn-pub/java/jce/8/jce_policy-8.zip
将解压的jar放到如下目录中,主要是local_policy.jar和US_export_policy.jar
$JAVA_HOME/jre/lib/security/
5.修改config.properties
coordinator=true
node-scheduler.include-coordinator=false
http-server.http.port=8999
query.max-memory=2GB
query.max-memory-per-node=1GB
discovery-server.enabled=true
discovery.uri=http://slave1:8999
http-server.authentication.type=KERBEROS
http.server.authentication.krb5.service-name=qun
http.server.authentication.krb5.keytab=/home/qun/presto-server-0.181/qun.keytab
http.authentication.krb5.config=/home/qun/presto-server-0.181/krb5.conf
http-server.https.enabled=true
http-server.https.port=7778
http-server.https.keystore.path=/home/qun/presto-server-0.181/qunkeystore.jks
http-server.https.keystore.key=keystorepd
| 配置项 | 描述 |
|---|---|
| http-server.authentication.type | Presto Coordinator的身份验证类型。必须设置为KERBEROS. |
| http.server.authentication.krb5.service-name | Presto Coordinator的 Kerberos 服务名称。必须与 Kerberos 主体匹配。 |
| http.server.authentication.krb5.principal-hostname | Presto Coordinator的 Kerberos 主机名。必须与 Kerberos 主体匹配。该参数是可选的。如果包含,Presto 将在 Kerberos 主体的主机部分中使用此值,而不是机器的主机名。 |
| http.server.authentication.krb5.keytab | 可用于验证 Kerberos 主体的密钥表的位置。 |
| http.authentication.krb5.config | Kerberos 配置文件的位置。 |
| http-server.https.enabled | 为 Presto 协调器启用 HTTPS 访问。应设置为true. |
| http-server.https.port | HTTPS 服务器端口。 |
| http-server.https.keystore.path | 将用于保护 TLS 的 Java 密钥库文件的位置。 |
| http-server.https.keystore.key | 密钥库的密码。这必须与您在创建密钥库时指定的密码相匹配。 |
6.修改Hive Connection
hive.properties
[root@hadoop102~] vim /opt/module/presto/etc/catalog/hive.properties
hive.metastore.authentication.type=KERBEROS
hive.metastore.service.principal=hive/hadoop102@EXAMPLE.COM
hive.metastore.client.principal=presto@EXAMPLE.COM
hive.metastore.client.keytab=/etc/security/keytab/presto.keytab
hive.hdfs.authentication.type=KERBEROS
hive.hdfs.impersonation.enabled=true
hive.hdfs.presto.principal=presto@EXAMPLE.COM
hive.hdfs.presto.keytab=/etc/security/keytab/presto.keytab
hive.config.resources=/opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml,/opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml
7.修改jvm.config
-server
-Xmx2G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-Dsun.security.krb5.debug=true
-Dlog.enable-console=true
修改完后重启presto集群和Hive MetaStore服务
8.连接presto集群
./presto-cli \
--server https://slave1:7778 \
--enable-authentication \
--krb5-config-path /etc/krb5.conf \
--krb5-principal qun@XIAOMI.PRESTO \
--krb5-keytab-path /home/qun/qun.keytab \
--krb5-remote-service-name qun \
--keystore-path /home/qun/qunkeystore.jks \
--keystore-password keystorepd
presto> select count(*) from mysql.test.user;
_col0
-------
1
(1 row)
Query 20170730_021003_00003_bpf6r, FINISHED, 1 node
Splits: 18 total, 18 done (100.00%)
0:00 [1 rows, 0B] [3 rows/s, 0B/s]
更换一台新的虚拟机slave3,添加一个新的principal:test1@XIAOMI.PRESTO,生成test1.keytab,然后访问presto集群
kadmin -p admin/admin -q "addprinc -randkey test1@XIAOMI.PRESTO"
kadmin -p admin/admin -q "ktadd -k /etc/test1.keytab test1@XIAOMI.PRESTO"
[test@slave3 ~]$ ./presto-cli \
> --server https://slave1:7778 \
> --enable-authentication \
> --krb5-config-path /etc/krb5.conf \
> --krb5-principal test1@XIAOMI.PRESTO \
> --krb5-keytab-path test1.keytab \
> --krb5-remote-service-name qun \
> --keystore-path qunkeystore.jks \
> --keystore-password keystorepd
presto> show catalogs;
Catalog
---------
mysql
system
(2 rows)
Query 20170801_134406_00005_wa4q4, FINISHED, 1 node
Splits: 1 total, 1 done (100.00%)
0:00 [0 rows, 0B] [0 rows/s, 0B/s]
presto> select count(*) from mysql.test.user;
_col0
-------
1
(1 row)
Query 20170801_134419_00006_wa4q4, FINISHED, 1 node
Splits: 18 total, 18 done (100.00%)
0:00 [1 rows, 0B] [3 rows/s, 0B/s]
更多presto安全性配置请参考官网。
性能优化
1.Presto优化之数据存储
1.1合理设置分区
与Hive类似,Presto会根据元数据信息读取分区数据,合理的分区能减少Presto数据读取量,提升查询性能。
1.2使用列式存储
Presto对ORC文件读取做了特定优化,因此在Hive中创建Presto使用的表时,建议采用ORC格式存储。相对于Parquet,Presto对ORC支持更好
1.3使用压缩
数据压缩可以减少节点间数据传输对IO带宽压力,对于即席查询需要快速解压,建议采用Snappy压缩。
2.Presto优化之查询SQL
2.1只选择使用的字段
由于采用列式存储,选择需要的字段可加快字段的读取、减少数据量。避免采用*读取所有字段。
2.2过滤条件必须加上分区字段
对于有分区的表,where语句中优先使用分区字段进行过滤。acct_day是分区字段,visit_time是具体访问时间。
[GOOD]: SELECT time, user, host FROM tbl where acct_day=20171101
[BAD]: SELECT * FROM tbl where visit_time=20171101
2.3Group By语句优化
合理安排Group by语句中字段顺序对性能有一定提升。将Group By语句中字段按照每个字段distinct数据多少进行降序排列。
[GOOD]: SELECT GROUP BY uid, gender
[BAD]: SELECT GROUP BY gender, uid
2.4Order by时使用Limit
Order by需要扫描数据到单个worker节点进行排序,导致单个worker需要大量内存。如果是查询Top N或者Bottom N,使用limit可减少排序计算和内存压力。
[GOOD]: SELECT * FROM tbl ORDER BY time LIMIT 100
[BAD]: SELECT * FROM tbl ORDER BY time
2.5使用Join语句时将大表放在左边
Presto中join的默认算法是broadcast join,即将join左边的表分割到多个worker,然后将join右边的表数据整个复制一份发送到每个worker进行计算。如果右边的表数据量太大,则可能会报内存溢出错误。
[GOOD] SELECT ... FROM large_table l join small_table s on l.id = s.id
[BAD] SELECT ... FROM small_table s join large_table l on l.id = s.id
3.注意事项
3.1字段名引用
避免和关键字冲突:MySQL对字段加反引号**`、**Presto对字段加双引号分割。当然,如果字段名称不是关键字,可以不加这个双引号。
3.2时间函数
对于Timestamp,需要进行比较的时候,需要添加Timestamp关键字,而MySQL中对Timestamp可以直接进行比较。
/*MySQL的写法*/
SELECT t FROM a WHERE t > '2017-01-01 00:00:00';
/*Presto中的写法*/
SELECT t FROM a WHERE t > timestamp '2017-01-01 00:00:00';
3.3不支持INSERT OVERWRITE语法
Presto中不支持insert overwrite语法,只能先delete,然后insert into。
3.4PARQUET格式
Presto目前支持Parquet格式,支持查询,但不支持insert。
二次开发
参考【2】
常见问题
- javax.net.ssl.SSLPeerUnverifiedException
presto> show catalogs;
Error running command: javax.net.ssl.SSLPeerUnverifiedException: Hostname 192.168.1.116 not verified:
certificate: sha256/i+KNkzrrH/NHzUruc9R+f0a/P8Ql/OhOKh9n3JtL1qg=
DN: CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown
subjectAltNames: []
解决办法:这种问题由keystore生成的时候host指定错误造成的,您的名字与姓氏是什么?[Unknown]: slave1,slave1即是hostname
2. Authentication failed for token
```shell
com.facebook.presto.server.security.SpnegoFilter Authentication failed for token
Encryption type AES256 CTS mode with HMAC SHA1-96 is not supported/enabled)
解决办法:下载JCE
http://www.oracle.com/technetwork/java/javase/downloads/jce8-download-2133166.html
解压后替换$JAVA_HOME/jre/lib/security目录下的local_policy.jar,US_export_policy.jar
- HDFS小文件问题
HDFS 小文件问题在大数据领域是个常见的问题。数仓 Hive 表有些表的文件有几千个,查询特别慢。Presto 下面这两个参数限制了 Presto 每个节点每个 Task 可执行的最大 Split 数目:
node-scheduler.max-splits-per-node=100
node-scheduler.max-pending-splits-per-task=10
- 多个列distinct的问题
--简单的说,正常的优化器应该使用 grouping sets 去将多个 group by 整合到一起来提升性能:
SELECT a1, a2,..., an, F1(b1), F2(b2), F3(b3), ...., Fm(bm), F1(distinct c1), ...., Fm(distinct cm) FROM Table GROUP BY a1, a2, ..., an
转换为
SELECT a1, a2,..., an, arbitrary(if(group = 0, f1)),...., arbitrary(if(group = 0, fm)), F(if(group = 1, c1)), ...., F(if(group = m, cm)) FROM
SELECT a1, a2,..., an, F1(b1) as f1, F2(b2) as f2,...., Fm(bm) as fm, c1,..., cm group FROM
SELECT a1, a2,..., an, b1, b2, ... ,bn, c1,..., cm FROM Table GROUP BY GROUPING SETS ((a1, a2,..., an, b1, b2, ... ,bn), (a1, a2,..., an, c1), ..., ((a1, a2,..., an, cm)))
GROUP BY a1, a2,..., an, c1,..., cm group
GROUP BY a1, a2,..., an
- 滴滴给我们总结了 Coordinator 常见的问题和解决方法:
-
使用HDFS FileSystem Cache导致内存泄漏,解决方法禁止FileSystem Cache,后续Presto自己维护了FileSystem Cache
-
Jetty导致堆外内存泄漏,原因是Gzip导致了堆外内存泄漏,升级Jetty版本解决
-
Splits太多,无可用端口,TIME_WAIT太高,修改TCP参数解决
-
Presto内核Bug,查询失败的SQL太多,导致Coordinator内存泄漏,社区已修复而 Presto Worker 主要用于计算,性能瓶颈点主要是内存和 CPU。内存方面通过三种方法来保障和查找问题:
-
通过Resource Group控制业务并发,防止严重超卖
-
通过JVM调优,解决一些常见内存问题,如Young GC Exhausted
-
参考
【1】https://prestodb.io/docs/current/(官网)
【2】https://tech.meituan.com/2014/06/16/presto.html(presto实现原理和美团最佳实践)
【3】Presto原理调优.pdf
【4】https://tanggaomeng.blog.csdn.net/article/details/112967839
【5】https://trino.io/docs/current/
【6】https://www.cnblogs.com/importbigdata/p/14254838.html
【7】https://blog.csdn.net/LW_Moving_Bricks/article/details/88984561
